
A language like Pig Latin helps users describe parallel data processing tasks in a simple and efficient way. It makes complex tasks easier to manage by hiding the complications of Hadoop’s MapReduce paradigm. With Pig, users can focus on the meaning of their data transformations, leading to better performance and increased productivity.
The flow of Pig in the Hadoop environment is as follows. It makes use of both the Hadoop Distributed File System, HDFS, and Hadoop’s processing system, MapReduce. In addition, there are 14 technologies involved in the Hadoop ecosystem. You can find more information about these technologies here.
The steps involved in executing a Pig script: By default, Pig reads input files from HDFS, uses HDFS to store intermediate data between MapReduce jobs, and writes its output to HDFS.
Let us see some important functionality of MapReduce
- MapReduce is a simple but powerful parallel data-processing paradigm.
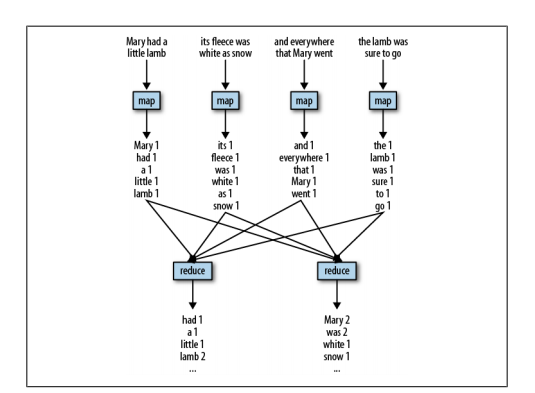
- Every job in MapReduce consists of three main phases: map, shuffle, and reduce. In the map phase, the application has the opportunity to operate on each record in the input separately.
- Many maps are started at once so that while the input may be gigabytes or terabytes in size, given enough machines, the map phase can usually be completed in under one
minute. The below flow tells you how the Map and reduce jobs work in data processing.
## The below is the sample Pig script
-- Load input from the file named Mary, and call the single
-- field in the record 'line'.
input = load 'mary' as (line);
-- TOKENIZE splits the line into a field for each word.
-- flatten will take the collection of records returned by
-- TOKENIZE and produce a separate record for each one, calling the single
-- field in the record word.
words = foreach input generate flatten(TOKENIZE(line)) as word;
-- Now group them together by each word.
grpd = group words by word;
-- Count them.cntd = foreach grpd generate group, COUNT(words);
-- Print out the results.
dump cntd;
Why Pig Latin is parallel data flow language
- Pig Latin is a data flow language. This means it allows users to describe how data from one or more inputs should be read, processed, and then stored to one or more outputs in parallel.
- These data flows can be simple linear flows like the word count example given previously. They can also be complex workflows that include points where multiple inputs are joined, and where data is split into multiple streams to be processed by different operators.
- To be mathematically precise, a Pig Latin script describes a directed acyclic graph (DAG), where the edges are data flows and the nodes are operators that process the data
Benefits
- Pig users can create custom functions to meet their particular processing
- Pig users can create custom functions to meet their particular processing Easily programmed Complex tasks involving interrelated data transformations can be simplified and encoded as data flow sequences.
- Pig programs accomplish huge tasks, but they are easy to write and maintain. Because the system automatically optimizes execution of Pig jobs, the user can focus on semantics.
Related Posts







You must be logged in to post a comment.