
The MapReduce concept is different from other distributed concepts. How Hadoop manages server failures is explained here.
Fault-tolerant Mechanism
- MapReduce does not achieve high scalability with distributed processing and high fault tolerance at the same time.
- Distributed computation is often a messy thing, so it is difficult to write a reliable distributed application by yourself.
- MapReduce is basically a two-way model. One is a map and the other one is a reducer.
Various kinds of failures are introduced when distributed applications are running: Some servers might fail abruptly, whereas some disks may get out of order. Keep in mind that writing code to handle failures by yourself is very time-consuming and can also cause new bugs in your application. You can read more on the Hadoop failed tasks.
Hadoop MapReduce, however, can take care of fault tolerance. When your application fails, the framework can handle the cause of failure and retry it or abort. Thanks to this feature, the application can complete its tasks while overcoming failures.
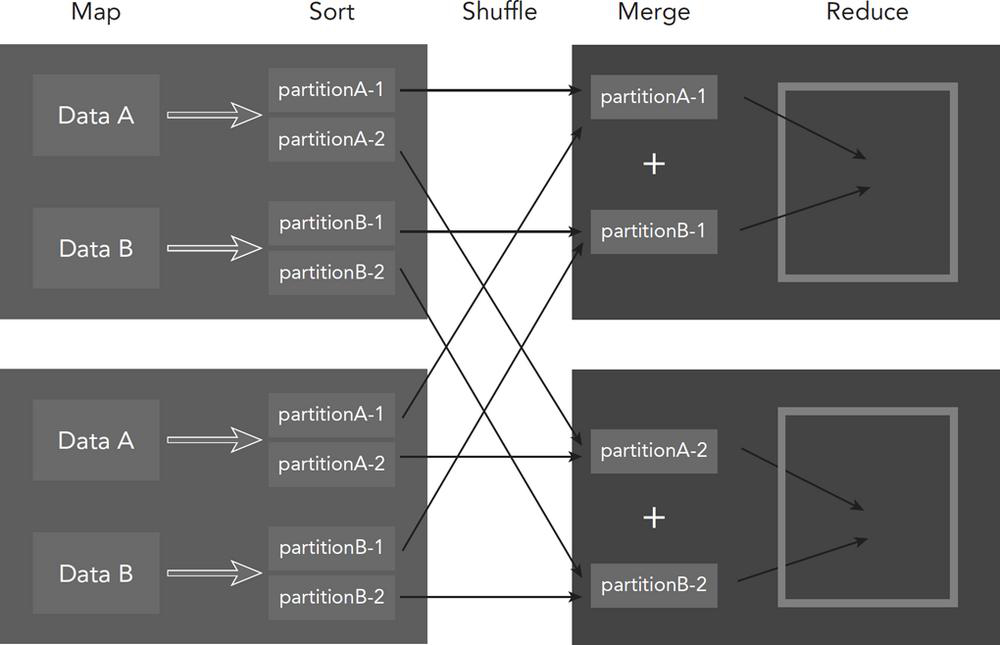
The Architecture of Hadoop MapReduce
Hadoop has three Unique features:
- High scalable
- High fault tolerance
- High-level interface to achieve these two points
The process of MapReduce comprises Five components:
- map: Read the data from a storage system such as HDFS.
- sort: Sort the input data from the map task according to their keys.
- shuffle: Divide the sorted data and repartitioning among cluster nodes.
- merge: Merge the input data sent from the mapper on each node.
- reduce: Read the merged data and integrate them into one result.
References:
Also, Read






